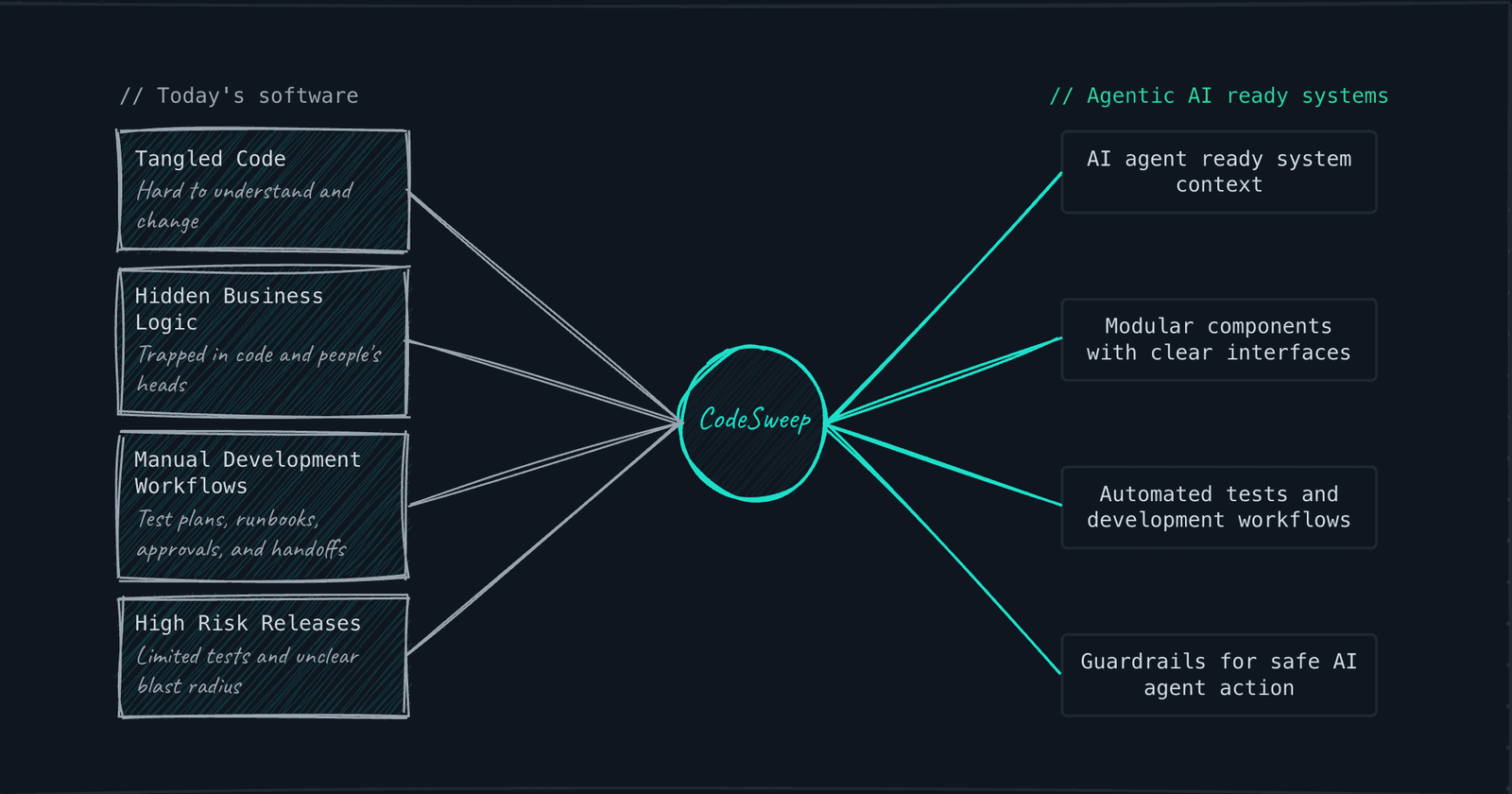
Mixture of Open-Weight Models with Iterative Patch Generation Improves Performance on SWE-bench
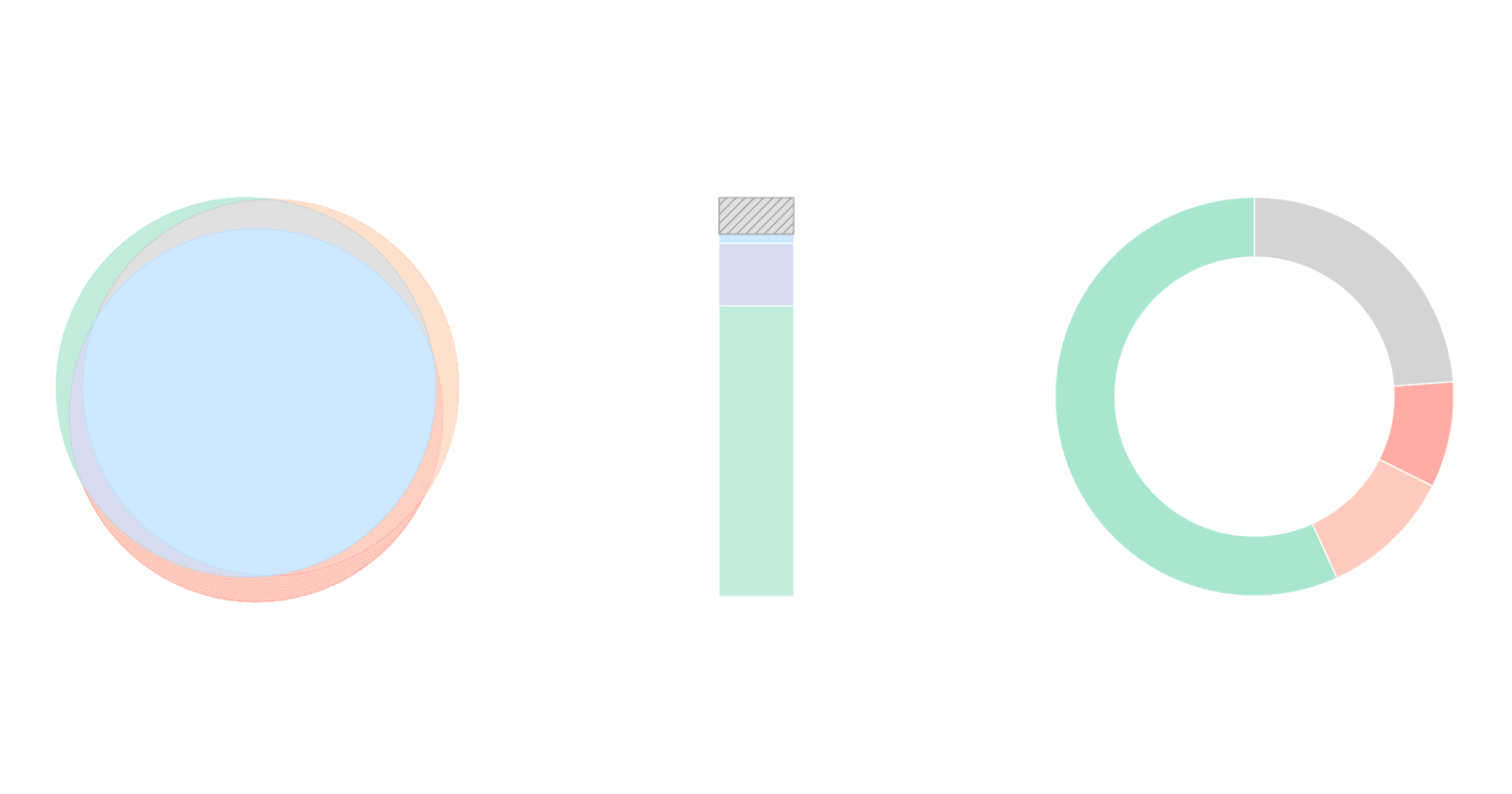
Goal
Our goal in this study was to explore whether a mixture of open-weight models, combined through an iterative process, can outperform any single model on the SWE-bench Verified benchmark. Specifically, we wanted to evaluate if patches generated by multiple models can provide a useful signal that improves subsequent rounds of patch generation.
Models
We selected three open-weight models for this experiment:
- Qwen3 Coder 480B A35B Instruct
- Kimi K2 Thinking
- Kimi K2 Instruct 0905
Each model had access to the same tool suite and was run under identical constraints to ensure fair comparison. We used Fireworks AI as the provider for these models.
Tools
All runs were conducted using our tool-calling scaffolding. This scaffolding is inspired by the SWE-agent tool-calling scaffolding.
Our scaffolding supports custom prompts for each iteration and circuit breakers in the agentic loop to account for factors like:
- Trajectory length
- Cost
- Consecutive timeouts
- Un-parsable model responses
The models were guided entirely by:
- Their “thinking”
- The tool-calls they generated
- The tool-call responses
The available tools were:
- str_replace_editor - a tool for viewing and editing files
- bash - a tool to provide the model access to a bash shell
- submit - a simple tool the model can call when it’s done with the task
The tool-calls were executed in docker containers based on the SWE-bench docker images.
Models did not receive information or hints outside of what these tools provided.
Methodology
Our process was carried out in three iterations.
Iteration 1 - Independent Model Runs
We first ran our tool-calling scaffolding with the three models independently. This gave us the first pool of candidate patches.
Iteration 2 - Single Model With Patches From Multiple Models
For the second iteration, we selected Kimi K2 Instruct 0905 as our single model. Its prompt was augmented with the patches produced in iteration 1.
The intuition is simple: if each model acts like a junior engineer exploring different directions, then collecting their patches provides additional structure that may give another model a better starting point.
Iteration 3 - Single Model Refinement
In the third iteration, we again used Kimi K2 Instruct 0905. Its prompt was augmented with the patch generated iteration 2.
The intuition is how an engineer might refine their own previous attempt: with additional context and a clearer search space, the model may be able to resolve more issues.
Handling Limits
When a circuit breaker was hit we needed to handle two scenarios:
- No files were edited — in this case a run did not produce a patch, we continued without it
- Files were edited, but the model didn't call the submit tool - in this case we proceeded by creating a patch with the available edits
Handling Patches From One Iteration To The Next
All iterations were performed sequentially with no intermediate ranking or categorization of patches. All patches generated in one iteration were passed into the subsequent iteration as an input.
Results
Using this mixture-of-models iterative approach, we observed consistent improvement over any individual model’s performance. With our scaffolding and methodology, we reached 70.4% in a pass@1 (per the SWE-bench definition) through the above agentic loop, which, at the time of writing (Dec 09, 2025), placed us second among all open-weight models on the SWE-bench Verified leaderboard.
A more detailed breakdown is included below.
Detailed Analysis
We wanted to see whether there was relative improvement (or regression) across the iterations. In order to do this, we used the SWE-bench harness to evaluate whether the intermediate patches were correct:
- Did they resolve the issue, and
- As we progressed through the iterations, did the resolution rate improve.
Note that this analysis was done after our final submission to the SWE-bench benchmark. Intermediate resolution evaluation was not used during the iteration runs themselves.
Iteration 1 - Mixture of Open-Weight Model Runs
Here we were curious about the relative performance of each open-weight model.

The model labels in the Venn diagram are as follows:
- Qwen3 Coder 480B A35B Instruct: q480b
- Kimi K2 Thinking: kimithink
- Kimi K2 Instruct 0905: kimi0905
You can see that more than half of the issues (56.8%) were resolved by all the models, a combination of any two models resolved another 10.8% of the issues and a single model resolved 8.6% of the issues, leaving an overall 23.8% unresolved in iteration one.
Consecutive Iterations
Next, we wanted to compare relative improvement or regressions across Iteration 1, 2 and 3.

As a baseline for Iteration 1 we used the 284 issues that all three models resolved. (Note: this is the strict intersection of issues resolved by all three models, not the total number of issues resolved across any model). For Iterations 2 and 3 we simply chose the number of issues resolved in that iteration, since these iterations only produced one patch per issue.
You can see from the Total Issues Resolved by Iteration bar chart that there is definitely improvement across the iterations. Across the three iterations we went from 284 issues resolved, to 345 issues resolved (plus 61) to the final submission of 354 issues (plus 9).
And you can see from the Regression vs New Fixes Between Iterations chart that while there are a small number of regressions (issues that were resolved in the prior iteration, but were not resolved in the current iteration), the net gain is still much greater. Iteration 2 had 5 regressions, but 66 new fixes and Iteration 3 had two regressions but 11 new fixes, still leading to an overall net gain.
Potential for Further Boosting Performance
One final question we wanted to answer was if we had an oracle that allowed us to select correct patches across all the iterations, how many issues would be resolved.

The answer is 390. This is 78% of the 500 SWE-bench Verified issues. At the time of writing (Dec 09, 2025) that would put this oracle second on the overall leaderboard (across open-weight and closed-weight models). This suggests that additional gains may be achievable through better patch selection, consensus methods, or reranking.
Conclusions and Future Work
We conclude that combining a mixture of open-weight models and running iterations definitely improves the overall system performance over any single model run on a benchmark like SWE-bench.
Each successive iteration improves performance over the previous iteration with a very small number of regressions.
The fact that the oracle potential after the final iteration is 36/500 issues (7.2%) suggests that there is an opportunity to further boost performance by exploring ways to pick correct candidate patches out of all the generated patches.